Mejorar el Rendimiento de RAG: Segmentación Consciente del Contexto desde Google Drive
El RAG tradicional a menudo sufre de segmentación de documentos de tamaño fijo, perdiendo valioso contexto y disminuyendo la precisión en la recuperación. Este flujo de trabajo aprovecha la IA para crear fragmentos de documentos conscientes del contexto desde Google Drive, transformándolos en embeddings enriquecidos en Pinecone para un rendimiento significativamente mejorado en aplicaciones RAG.
Documentation
RAG: Segmentación Consciente del Contexto desde Google Drive a Pinecone
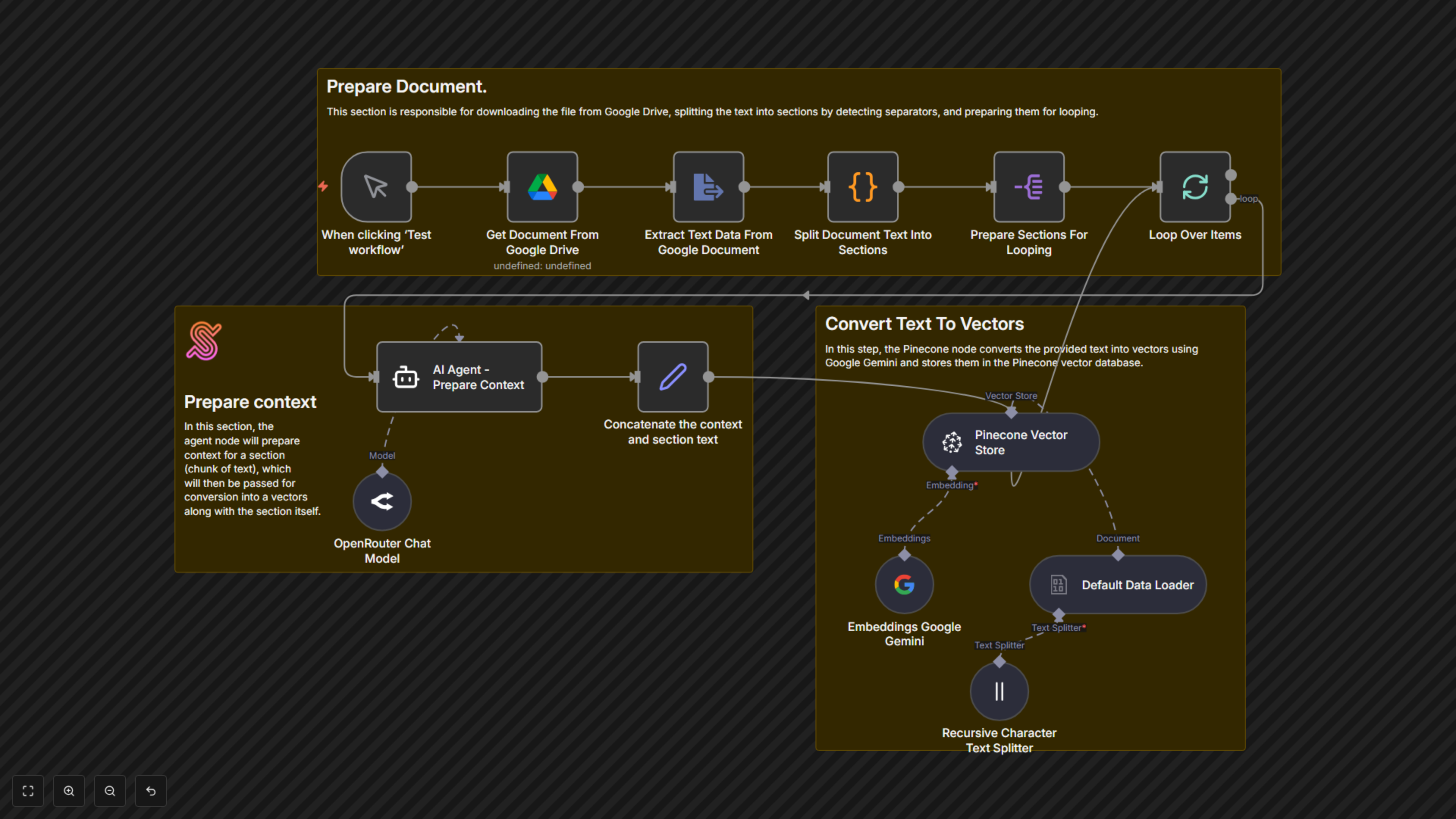
Este flujo de trabajo de n8n automatiza el proceso crucial de preparar documentos para sistemas avanzados de Generación Aumentada por Recuperación (RAG). Divide inteligentemente los documentos, enriquece cada sección con contexto generado por IA y los almacena como vectores, garantizando que sus aplicaciones RAG entreguen información altamente relevante y precisa.
Características Clave
- Ingesta Automática de Documentos de Google Drive: Extraiga documentos directamente de su Google Drive de forma fluida.
- Seccionamiento Inteligente de Documentos: Divide documentos grandes en secciones manejables basadas en separadores definidos.
- Generación de Contexto Potenciada por IA: Utiliza un agente IA (mediante OpenRouter y Gemini) para crear resúmenes breves y ricos en contexto para cada fragmento de documento.
- Embeddings Vectoriales Mejorados: Combina contenido original con contexto generado por IA para embeddings más ricos y precisos.
- Integración con la Base de Datos Vectorial Pinecone: Almacena automáticamente vectores conscientes del contexto en su índice Pinecone, optimizado para RAG.
- Mejora del Rendimiento de RAG: Incrementa la relevancia y precisión de la información recuperada por sus aplicaciones RAG.
Cómo Funciona
Este flujo de trabajo inicia mediante un disparador manual o programado. Primero, descarga un documento especificado desde Google Drive y extrae su contenido de texto. Luego, un paso de código personalizado divide el documento en secciones lógicas usando un separador predefinido (—---------------------------—-------------[SECTIONEND]—---------------------------—-------------). Cada sección se procesa en un ciclo: un agente IA (impulsado por OpenRouter y embeddings de Google Gemini) genera un resumen contextual conciso para ese fragmento específico, haciendo referencia a todo el documento para asegurar precisión. Este contexto generado por IA se antepone al texto original del fragmento. Finalmente, este fragmento consciente del contexto se convierte en un embedding vectorial usando Google Gemini y se almacena en su base de datos vectorial Pinecone. Este proceso asegura que cada fragmento almacenado contenga información contextual vital, mejorando significativamente la calidad de recuperación para aplicaciones RAG.