Automatiza la Recolección de Datos del SERP de Google para Análisis SEO
Rastrear manualmente las posiciones de búsqueda en Google y las posiciones de los competidores es un proceso que consume mucho tiempo y es propenso a errores. Este flujo de trabajo automatiza la extracción de datos completos del SERP de Google para palabras clave específicas, proporcionando información precisa para el análisis SEO y la toma de decisiones estratégicas.
Documentation
Automatiza la Recolección de Datos del SERP de Google para Investigación SEO
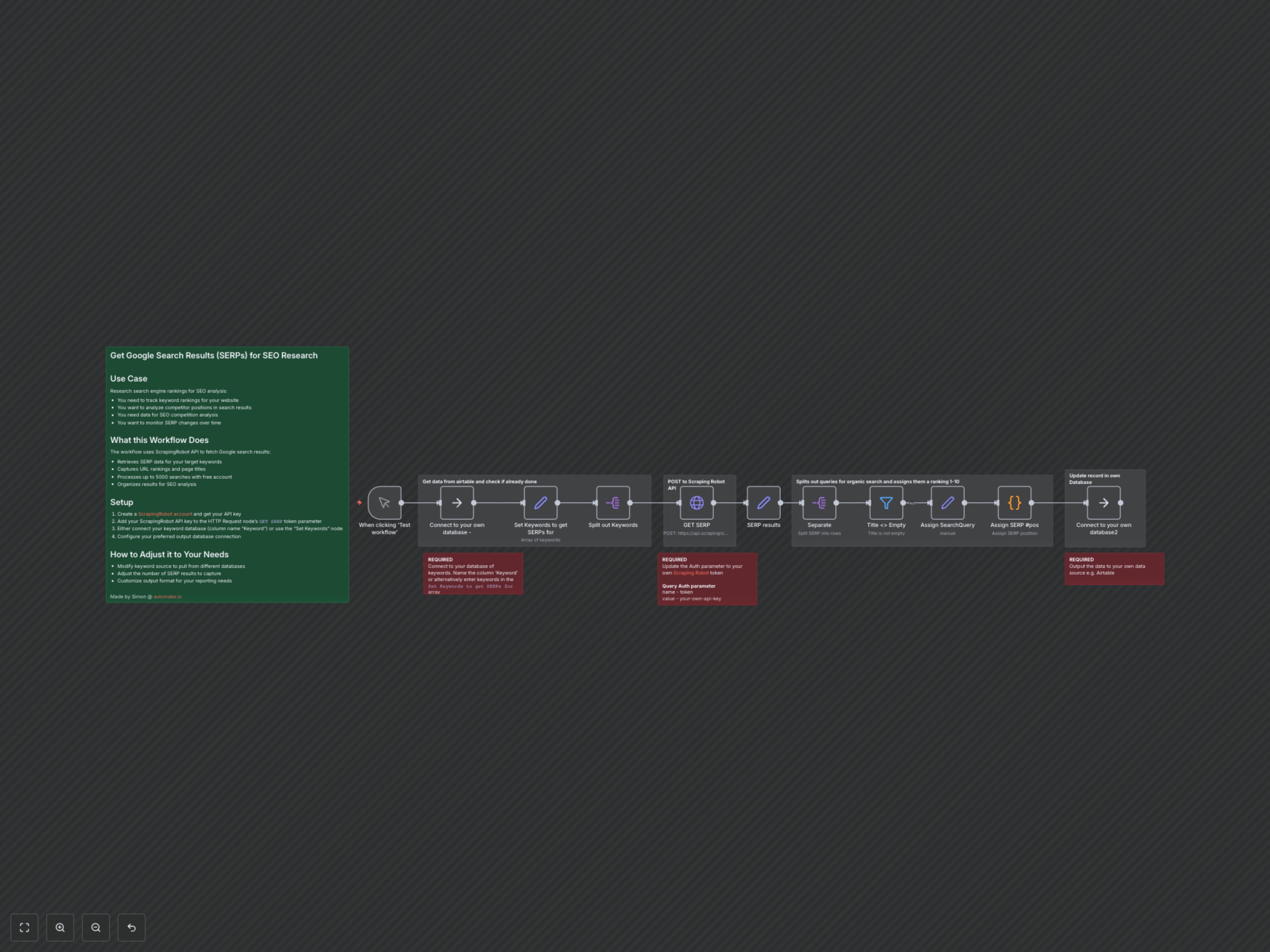
El seguimiento de las posiciones en motores de búsqueda y el análisis del rendimiento de los competidores son fundamentales para un SEO efectivo, pero la recolección manual de datos consume mucho tiempo y es propensa a errores. Este flujo de trabajo agiliza tu investigación SEO al extraer automáticamente datos completos del SERP (Página de Resultados del Motor de Búsqueda) de Google para cualquier lista de palabras clave, entregando información procesable directamente a tu base de datos.
Características Clave
- Extracción automatizada de resultados de búsqueda orgánicos, anuncios pagados y secciones "La gente también pregunta".
- Asignación precisa de las posiciones de resultados orgánicos (1-10) para un análisis exacto del ranking.
- Entrada flexible de palabras clave: integra con tus bases de datos existentes (por ejemplo, Airtable) o define palabras clave directamente dentro del flujo de trabajo.
- Salida de datos optimizada hacia tu base de datos preferida para análisis o reportes.
Cómo Funciona
1. Entrada de Palabras Clave: El flujo de trabajo comienza con una lista de palabras clave, ya sea de un array predefinido dentro del flujo o conectando con una base de datos externa de palabras clave. 2. Obtención del SERP: Para cada palabra clave, se envía una solicitud HTTP POST a la API de ScrapingRobot, usando su módulo GoogleScraper para realizar una búsqueda en Google en tiempo real. 3. Extracción de Datos: La respuesta JSON cruda de ScrapingRobot se procesa para extraer meticulosamente los elementos clave del SERP, incluyendo resultados orgánicos (título, URL), anuncios pagados y preguntas comunes de la sección "La gente también pregunta". 4. Asignación de Ranking: Posteriormente, se aíslan los resultados orgánicos, se filtran los títulos válidos, y un nodo de código JavaScript personalizado asigna una posición numérica precisa (1-10) a cada resultado basado en su ranking para esa palabra clave específica. 5. Integración con la base de datos: Finalmente, los datos del SERP estructurados y enriquecidos, con las posiciones asignadas, son enviados a la base de datos de salida designada, listos para análisis SEO profundos, reportes y seguimiento.