Automatiza la generación de llms.txt listo para IA a partir de rastreos de Screaming Frog
Extraer y estructurar manualmente el contenido del sitio web para el entrenamiento de LLM o el descubrimiento de contenido es una tarea compleja y que consume mucho tiempo. Este flujo de trabajo automatiza la generación de archivos `llms.txt` a partir de rastreos de Screaming Frog, asegurando una indexación óptima del contenido para modelos de IA y ahorrando un esfuerzo manual significativo.
Documentation
Generar archivos llms.txt listos para IA a partir de rastreos de sitios web con Screaming Frog
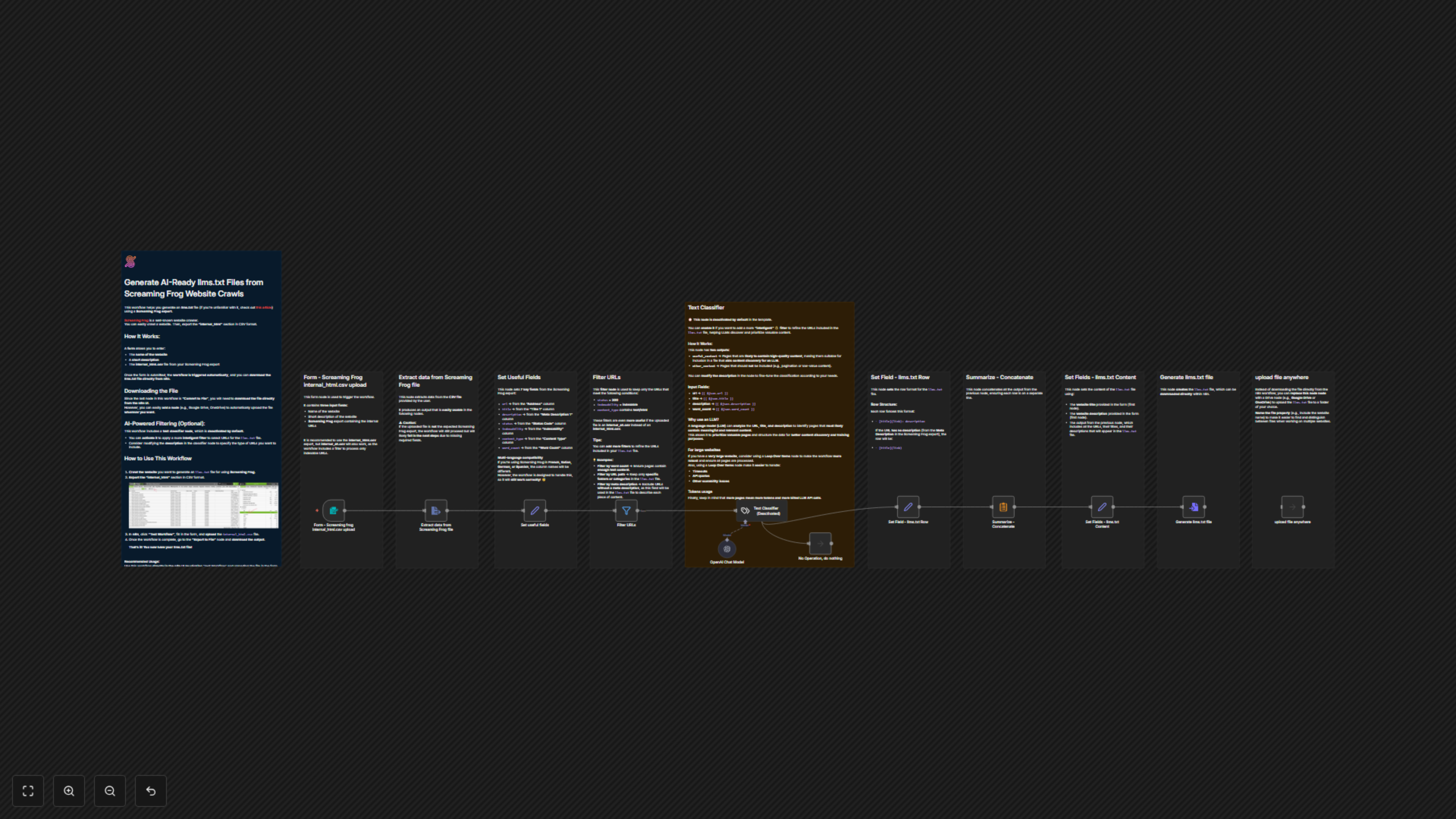
Este flujo de trabajo de n8n simplifica el proceso de creación de archivos llms.txt, esenciales para guiar a los Modelos de Lenguaje Extenso (LLMs) hacia contenido valioso en tu sitio web. Al aprovechar los datos exportados desde Screaming Frog SEO Spider, asegura que tus modelos de IA descubran y prioricen eficientemente páginas web de alta calidad para entrenamiento o generación de contenido.
Características principales
- Generación automatizada de archivos llms.txt desde las exportaciones internal_html.csv o internal_all.csv de Screaming Frog.
- Filtrado inteligente de URLs basado en estado, indexabilidad y tipo de contenido para incluir solo páginas relevantes y de alta calidad.
- Compatibilidad multilingüe para exportaciones de Screaming Frog (inglés, francés, italiano, alemán, español).
- Clasificación de texto potenciada por IA (opcional, usando OpenAI/LangChain) para un filtrado avanzado del contenido, garantizando que los LLMs se enfoquen en las páginas más valiosas.
- Formato de salida llms.txt personalizable, incluyendo nombre del sitio web, descripción, URL, título y meta descripción.
Cómo funciona
El flujo de trabajo comienza con un formulario simple donde los usuarios suben su exportación CSV de Screaming Frog y proporcionan detalles básicos del sitio web. Luego extrae campos clave de datos (URL, título, descripción, estado, indexabilidad, tipo de contenido, conteo de palabras) desde el CSV, gestionando inteligentemente nombres de columnas multilingües. Un filtro robusto selecciona solo páginas HTML indexables con estado HTTP 200. Opcionalmente, un clasificador de texto IA puede refinar aún más esta selección, categorizando páginas como 'useful_content' o 'other_content'. Finalmente, compila los datos filtrados en el formato especificado llms.txt, listo para descargar o subir automáticamente al almacenamiento en la nube.