Construisez une base de connaissances IA et un système de Q&R à partir de contenu web automatiquement
La curation manuelle et la recherche à travers un contenu en ligne étendu pour des réponses spécifiques est un processus long et sujet à erreurs. Ce flux de travail automatise l’ingestion d’articles web dans un magasin vectoriel Milvus, permettant à un système de Q&R propulsé par l’IA de fournir des réponses instantanées et contextualisées.
Documentation
Construisez un système de Q&R propulsé par IA à partir de n’importe quel contenu web
Transformez facilement du contenu web brut en une base de connaissances dynamique et consultable. Ce puissant flux n8n profite aux chercheurs, gestionnaires de contenu, et à toute personne ayant besoin de réponses rapides et précises à partir de vastes ressources en ligne, en automatisant l’ingestion des données et la Q&R pilotée par IA.
Fonctionnalités clés
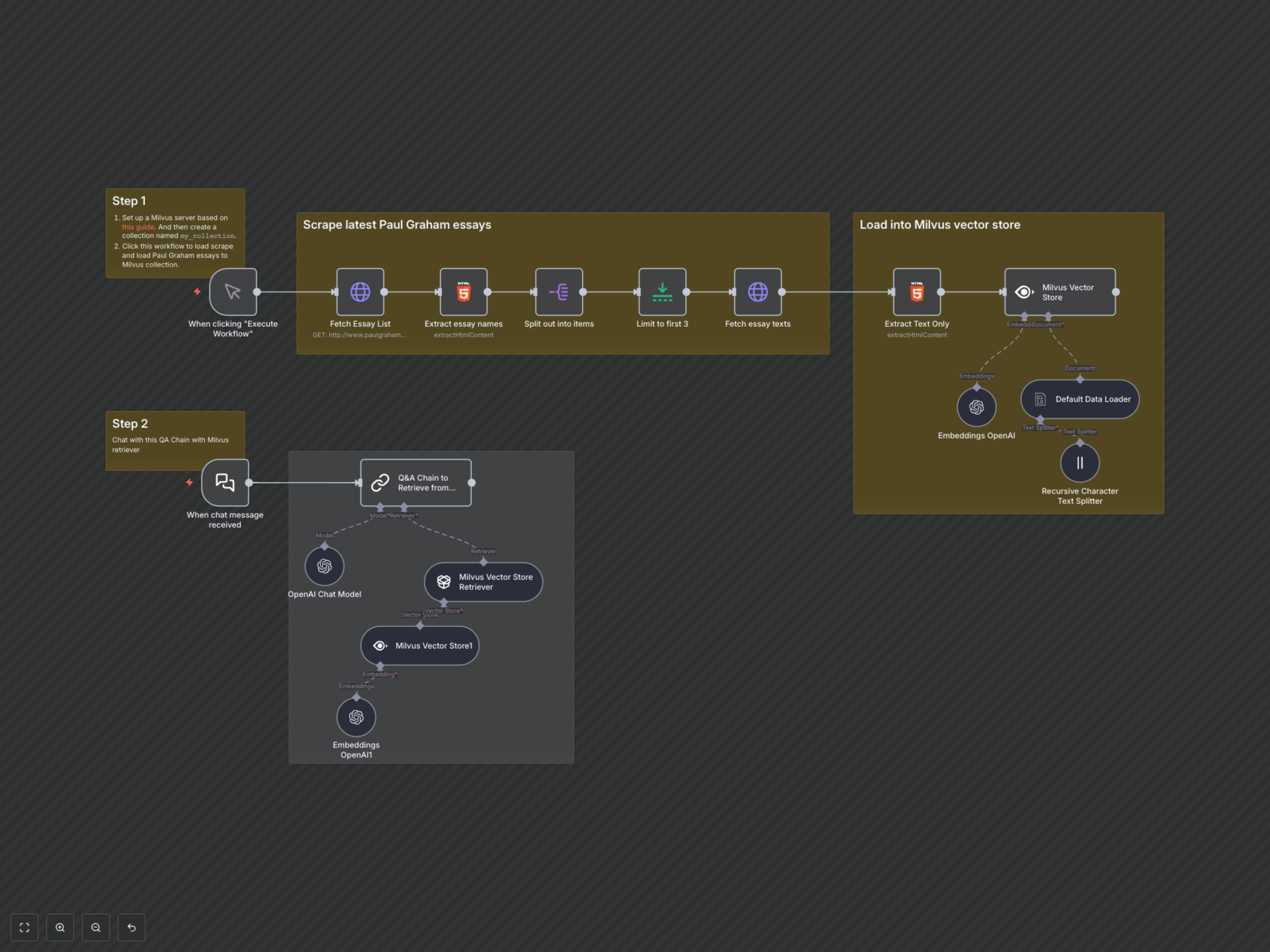
- Extraction web automatisée : Extrayez facilement les liens d’articles et leur contenu de n’importe quelle URL spécifiée.
- Traitement intelligent du texte : Nettoie et découpe le texte HTML brut pour une meilleure compréhension par l’IA.
- Embeddings OpenAI : Convertit le texte en vecteurs sémantiques pour une recherche avancée de similarité.
- Intégration du magasin vectoriel Milvus : Stocke et indexe le contenu pour un accès ultra-rapide.
- Q&R propulsée par IA : Exploitez LangChain et OpenAI pour répondre aux questions contextuellement depuis votre base de connaissances personnalisée.
- Interface de chat : Interagissez avec votre base de connaissances via un déclencheur de chat simple.
Comment ça fonctionne
Ce flux de travail opère en deux phases principales : Ingestion de la base de connaissances et Q&R propulsée par IA. La phase d’ingestion commence par un déclencheur manuel qui récupère une liste d’articles depuis un site cible. Elle scrape ensuite séquentiellement le contenu de chaque article, extrait uniquement le texte pertinent, puis le divise en morceaux plus petits et gérables. OpenAI génère des embeddings vectoriels pour ces morceaux de texte, qui sont ensuite stockés dans une base de données vectorielle Milvus, formant ainsi votre base de connaissances consultable. La phase de Q&R est activée par un message de chat. Lors de la réception d’une requête, le flux génère un embedding correspondant, recherche dans le magasin vectoriel Milvus un contenu sémantiquement similaire, et utilise un modèle de chat OpenAI (orchestré par une chaîne LangChain de Q&R) pour synthétiser une réponse précise et contextualisée basée sur l’information retrouvée.