Extraction Web Pilotée par IA vers Google Sheets : Capture Instantanée des Données
L'extraction manuelle des données produit à partir des sites web est un processus long et sujet à erreurs. Ce workflow automatise l'extraction web et utilise l'IA pour extraire avec précision les détails des produits, les organisant de manière fluide dans une feuille Google Sheets pour une gestion facile des données.
Documentation
Extraction Web Pilotée par IA vers Google Sheets : Capture Instantanée des Données
Ce workflow puissant automatise le processus fastidieux d'extraction d'informations produit depuis les sites web. Il extrait intelligemment les pages, utilise l'IA pour identifier les détails clés, puis organise proprement toutes les données collectées directement dans vos Google Sheets, économisant ainsi un temps précieux pour la recherche de marché, l'analyse concurrentielle ou la mise à jour des inventaires.
Fonctionnalités Clés
- Extraction Web Automatisée : Utilise Jina AI pour récupérer efficacement un contenu propre et lisible de toute page web cible, surmontant les défis courants du scraping.
- Extraction de Données Intelligente : Exploite OpenAI et LangChain pour identifier et extraire précisément des détails spécifiques des produits comme le titre, le prix, la disponibilité, l’image et l’URL du produit à partir d’un texte non structuré.
- Sortie de Données Structurée : Transforme les données brutes extraites en un format JSON cohérent et utilisable, facilitant le traitement en aval.
- Intégration Transparente avec Google Sheets : Ajoute automatiquement toutes les données produits collectées directement dans votre Google Sheet spécifié pour un stockage et une analyse centralisés.
- Automatisation Sans Code : Configurez et personnalisez des tâches complexes de scraping web sans écrire une seule ligne de code, rendant la collecte avancée de données accessible.
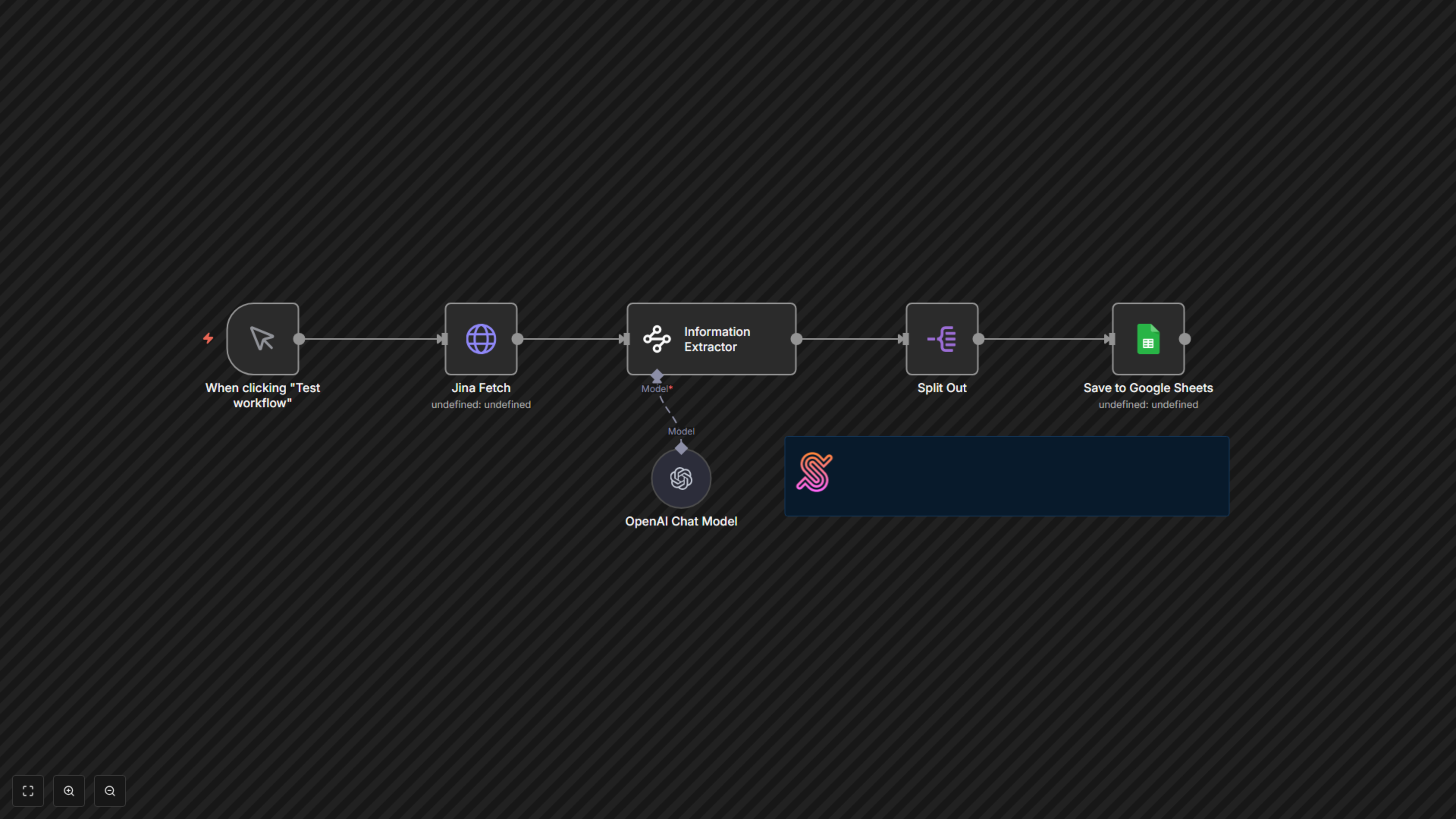
Comment Ça Fonctionne
Ce workflow commence par un déclencheur manuel, vous permettant d'initier le processus d'extraction à la demande. D'abord, le nœud Jina Fetch récupère le contenu de la page web cible, fournissant une version propre et prête pour l'IA. Ensuite, le nœud Information Extractor, alimenté par un modèle de langage OpenAI (connecté via le nœud OpenAI Chat Model), analyse intelligemment le contenu de la page selon un schéma prédéfini pour extraire des détails spécifiques tels que le titre du livre, le prix, la disponibilité, l’URL de l’image, et l’URL du produit. Les données extraites, qui sont une série de résultats, sont ensuite traitées par le nœud Split Out, s’assurant que les informations de chaque produit sont gérées individuellement. Enfin, le nœud Save to Google Sheets ajoute ces données produit structurées dans votre Google Sheet choisi, vous fournissant un ensemble de données continuellement mis à jour et organisé.