Automate RAG AI Agent with Milvus, Cohere & Google Drive
Empower your RAG AI agent with automatically updated knowledge from Google Drive, reducing manual data preparation by 100% and accelerating response accuracy.
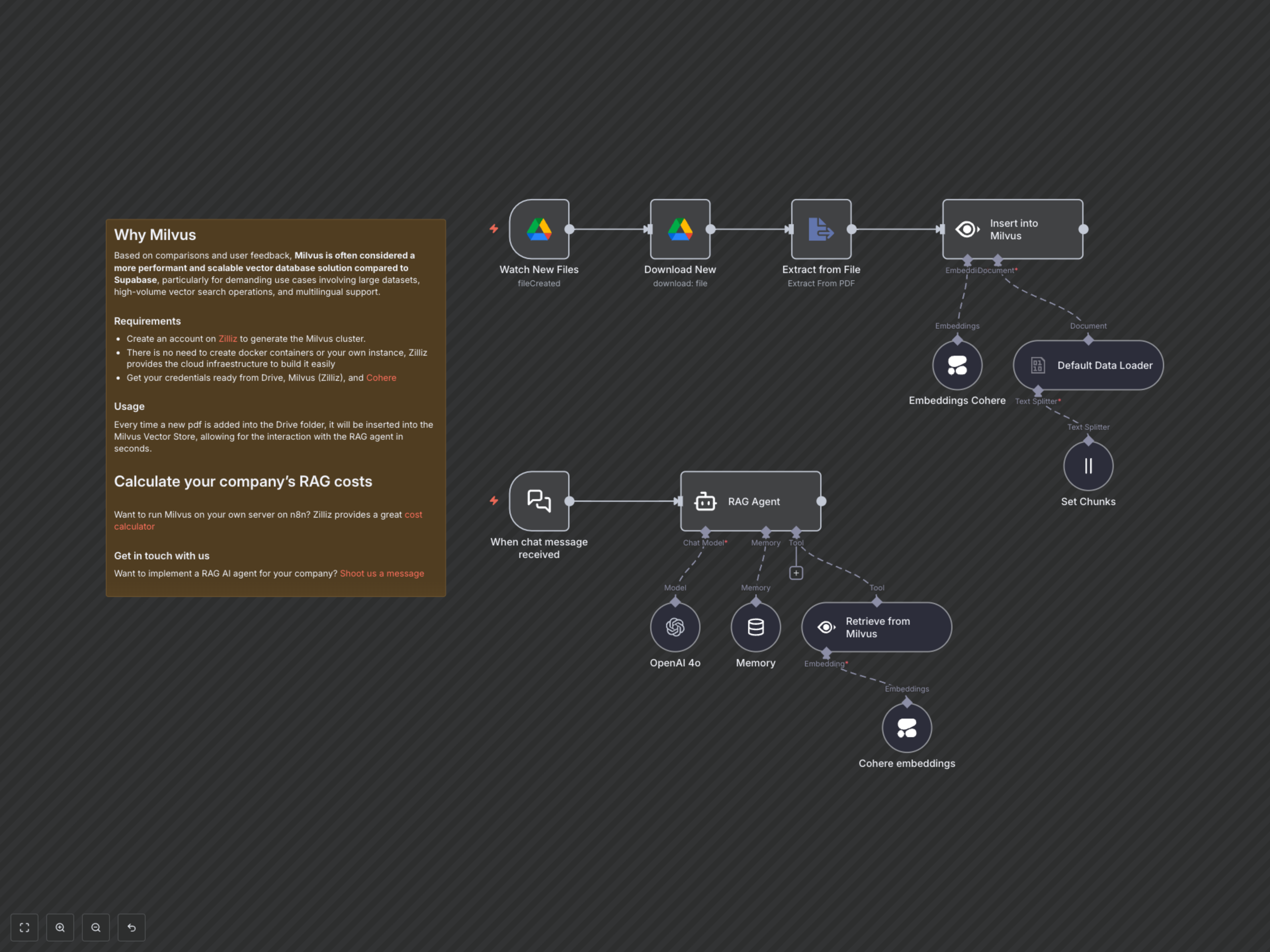
Manually updating AI knowledge bases and ensuring relevant document retrieval for AI agents is time-consuming. This workflow automatically ingests new PDFs from Google Drive into a Milvus vector store, enabling a RAG AI agent to provide real-time, context-aware responses.
Build a Dynamic RAG AI Agent with Milvus, Cohere, and Google Drive
This advanced n8n workflow empowers you to create and maintain a highly accurate RAG (Retrieval Augmented Generation) AI agent with an automatically updated knowledge base. By seamlessly integrating Google Drive, Milvus, Cohere embeddings, and OpenAI, your agent delivers real-time, contextually relevant responses from your latest documents.
Key Features
- Automated PDF ingestion from designated Google Drive folders.
- Intelligent text extraction and optimal chunking for vectorization.
- High-quality multilingual embeddings generated by Cohere for semantic search.
- Scalable vector storage and retrieval using Milvus, optimized for large datasets.
- Dynamic RAG agent powered by OpenAI (GPT-4o) for informed conversations.
- Maintains chat history and context with built-in memory for seamless interactions.
How It Works
The workflow operates in two distinct, yet interconnected, phases: Automated Data Ingestion and Intelligent AI Interaction.
Automated Data Ingestion: Upon detection of a new PDF file in your specified Google Drive folder, the workflow automatically downloads, extracts, and intelligently chunks its content. Cohere's multilingual embedding model then transforms these chunks into high-quality vector embeddings, which are efficiently stored alongside their source text in your Milvus vector database. This process ensures your AI agent's knowledge base is always current with your latest information.
Intelligent AI Interaction: When your RAG agent receives a chat query via its dedicated webhook, it leverages Cohere embeddings to perform a semantic search within your Milvus vector store. It retrieves the most pertinent documents, combines them with the user's query and the ongoing conversation history (managed by the memory node), and then feeds this rich context to OpenAI's GPT-4o. The result is a highly accurate, context-aware, and data-driven response, directly informed by your proprietary documents.