Sync Notion Pages to Supabase Vector DB for AI-Powered Search
Automatically transform Notion content into AI-ready vector embeddings in Supabase, reducing manual data preparation time by over 90% and instantly enhancing AI application capabilities.
Manually transforming Notion knowledge into an AI-ready vector database is a tedious and time-consuming process. This workflow automatically captures new Notion pages, generates precise OpenAI embeddings, and stores them in Supabase, instantly enabling a powerful, AI-ready knowledge base.
Documentation
Sync Notion Pages to Supabase Vector DB with OpenAI
This powerful n8n workflow bridges your Notion knowledge base with the world of AI, automatically converting your critical Notion pages into vector embeddings stored in Supabase. Ideal for building custom AI chatbots, semantic search engines, or RAG (Retrieval-Augmented Generation) applications that require up-to-date information from your internal knowledge. Forget manual data export and processing; this workflow ensures your AI applications always have access to the latest, vectorized Notion content.
Key Features
- Automated synchronization: Monitors your Notion database for new pages and processes them instantly.
- Intelligent content extraction: Retrieves all block content from Notion pages, filtering out non-text elements like images and videos.
- Advanced text chunking: Divides content into optimal token chunks (256 tokens with 30 overlap) for high-quality embeddings and retrieval.
- OpenAI-powered embeddings: Leverages OpenAI's robust models to generate precise vector embeddings for semantic understanding.
- Supabase integration: Stores vectorized Notion content along with crucial metadata (page ID, title, creation time) in your Supabase vector database.
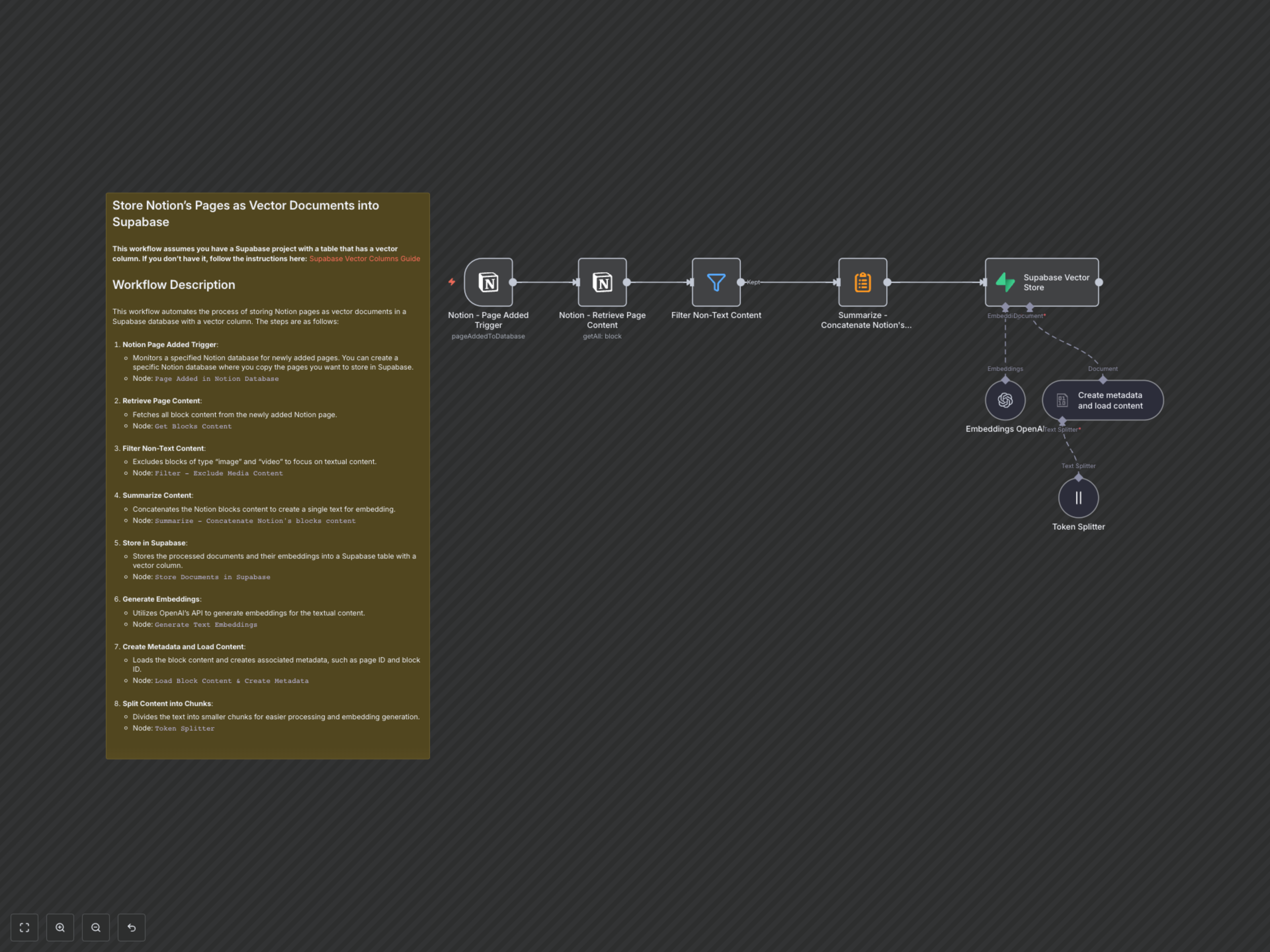
How It Works
This workflow is triggered every time a new page is added to a specified Notion database. First, it retrieves all content blocks from the newly added page. Non-textual content like images and videos are filtered out to ensure only relevant text is processed. The remaining text blocks are then concatenated into a single document. Before generating embeddings, the workflow creates metadata (page ID, title, creation time) and loads the content. This content is then intelligently split into smaller, optimized chunks using a token splitter. Each chunk is sent to OpenAI's embedding API to generate its vector representation. Finally, these text chunks, their corresponding vector embeddings, and their rich metadata are securely stored in your Supabase vector database, ready for advanced AI applications.