Optimieren Sie die LLM-Bewertung mit paralleler Leistungsüberwachung
Das manuelle Vergleichen von LLM-Ausgaben verschiedener Modelle ist zeitaufwendig und es fehlt eine strukturierte Bewertung. Dieser n8n-Workflow automatisiert den parallelen Vergleich von LLM-Ausgaben und protokolliert die Antworten in Google Sheets für eine effiziente Teambewertung und datenbasierte Modellauswahl.
Documentation
Schnellere LLM-Bewertung und -Auswahl freischalten
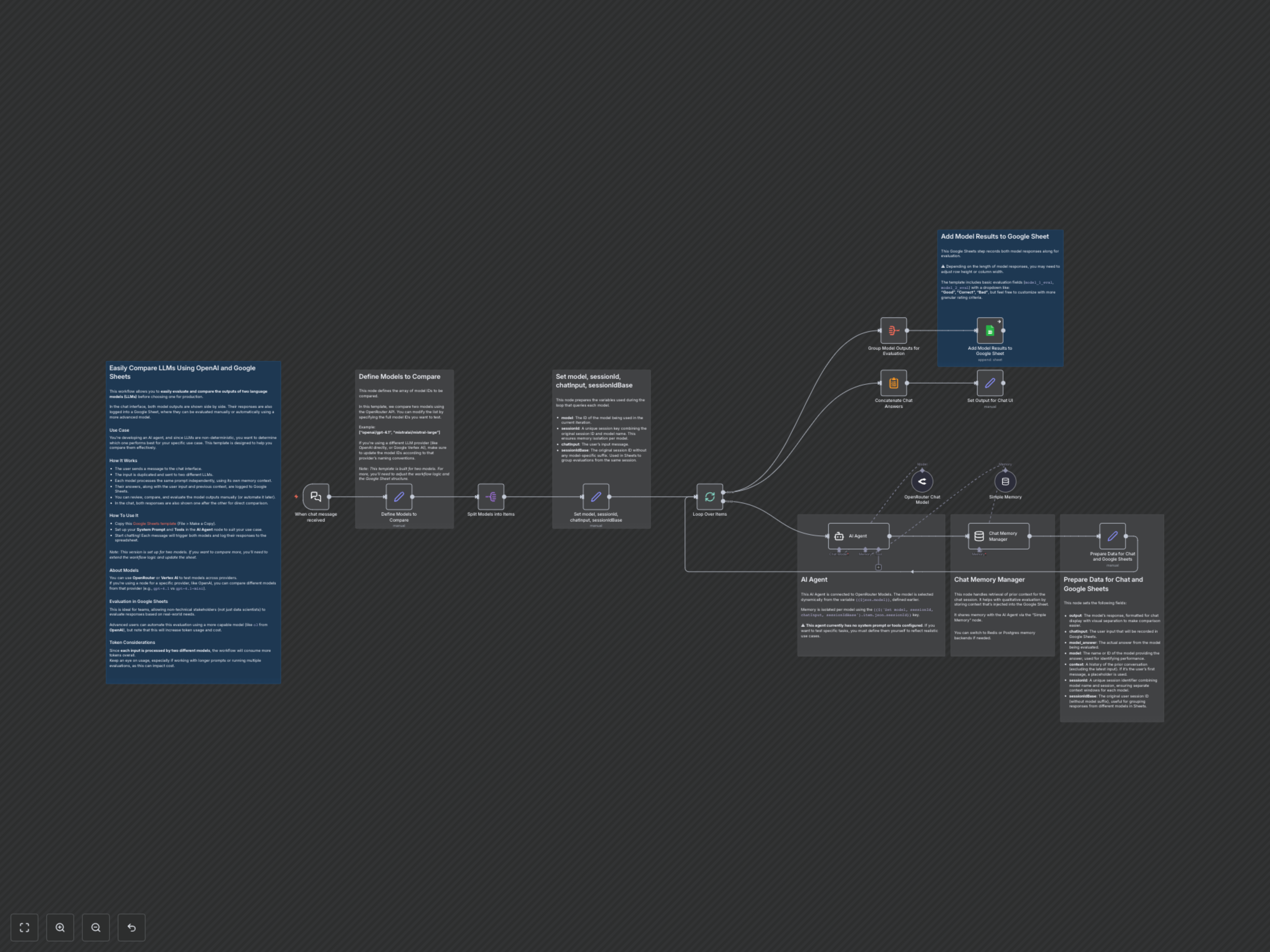
Die Entwicklung effektiver KI-Agenten erfordert eine sorgfältige Auswahl von Large Language Models (LLMs). Dieser n8n-Workflow bietet eine robuste Lösung zum parallelen Vergleich verschiedener LLMs, zur Erfassung ihrer Antworten und zur Protokollierung für eine strukturierte Bewertung in Google Sheets, damit Teams datengetriebene Entscheidungen treffen können.
Wesentliche Funktionen
- Paralleler LLM-Vergleich: Automatisches Senden derselben Eingabeaufforderung gleichzeitig an zwei unterschiedliche LLMs, um sofort vergleichbare Ausgaben zu erzielen.
- Dynamische Modellauswahl: Einfache Konfiguration und Wechsel zwischen verschiedenen LLMs (z.B. OpenAI, Mistral, verschiedene Versionen) über die OpenRouter API oder spezifische Anbieterknoten.
- Isolierter Speicher-Kontext: Jeder LLM verwaltet seinen eigenen Gesprächsspeicher, um eine faire und genaue Bewertung von mehrstufigen Interaktionen zu gewährleisten.
- Strukturierte Datenprotokollierung: Automatisches Protokollieren von Benutzereingaben, Modellergebnissen und Gesprächskontext in einem Google Sheet für umfassende Teamüberprüfung und manuelle oder automatisierte Bewertung.
- Echtzeit-Chat-Vergleich: Sofortige Anzeige beider Modellantworten in der Chat-Oberfläche nach der Eingabe, um eine schnelle qualitative Bewertung zu ermöglichen.
- Teamfreundliche Bewertung: Ermöglichen Sie auch nicht-technischen Beteiligten eine einfache Bewertung der Modellleistung anhand vordefinierter Kriterien in Google Sheets.
Funktionsweise
Beim Empfang einer Chatnachricht dupliziert der Workflow die Eingabe und sendet sie an zwei vordefinierte Large Language Models. Jedes Modell verarbeitet die Eingabe unabhängig und nutzt seinen eigenen Gesprächsspeicher. Die jeweiligen Antworten, zusammen mit der ursprünglichen Benutzereingabe und dem vorherigen Chat-Kontext, werden gleichzeitig in einem dafür vorgesehenen Google Sheet für eine detaillierte Analyse protokolliert. Gleichzeitig werden beide Modellantworten nacheinander in der Chat-Oberfläche angezeigt, wodurch ein sofortiger Vergleich nebeneinander möglich ist. Dieser systematische Ansatz optimiert den Bewertungsprozess und ermöglicht eine effiziente Identifikation des besten LLMs für Ihren spezifischen Anwendungsfall.