Automatisieren der OpenAI-Zitatformattierung für RAG-Genauigkeit
Manuelle Extraktion und Formatierung von Zitaten aus OpenAI-Assistenten kann mühsam sein, was zu Ungenauigkeiten führt und die Inhaltslieferung verlangsamt. Dieser Arbeitsablauf automatisiert die Abrufung und dynamische Formatierung von Zitaten aus Ihrem OpenAI-Vektorspeicher und stellt sicher, dass jede von KI generierte Antwort präzise belegt und sofort einsatzbereit ist.
Documentation
Automatisieren der OpenAI-Zitatformattierung für RAG-Genauigkeit
KI-Assistenten sind zwar leistungsstark, haben jedoch oft Schwierigkeiten bei der präzisen Generierung von Zitaten und der Quellenangabe, was zu Inhalten führt, die an Glaubwürdigkeit mangeln oder umfangreiche manuelle Überprüfungen erfordern. Dieser n8n-Arbeitsablauf löst dieses Problem, indem er den Abruf und die dynamische Formatierung von Zitaten aus OpenAI-Vektorspeicherdateien vollständig automatisiert und so rohe KI-Ausgaben in professionell referenzierte Inhalte verwandelt.
Hauptmerkmale
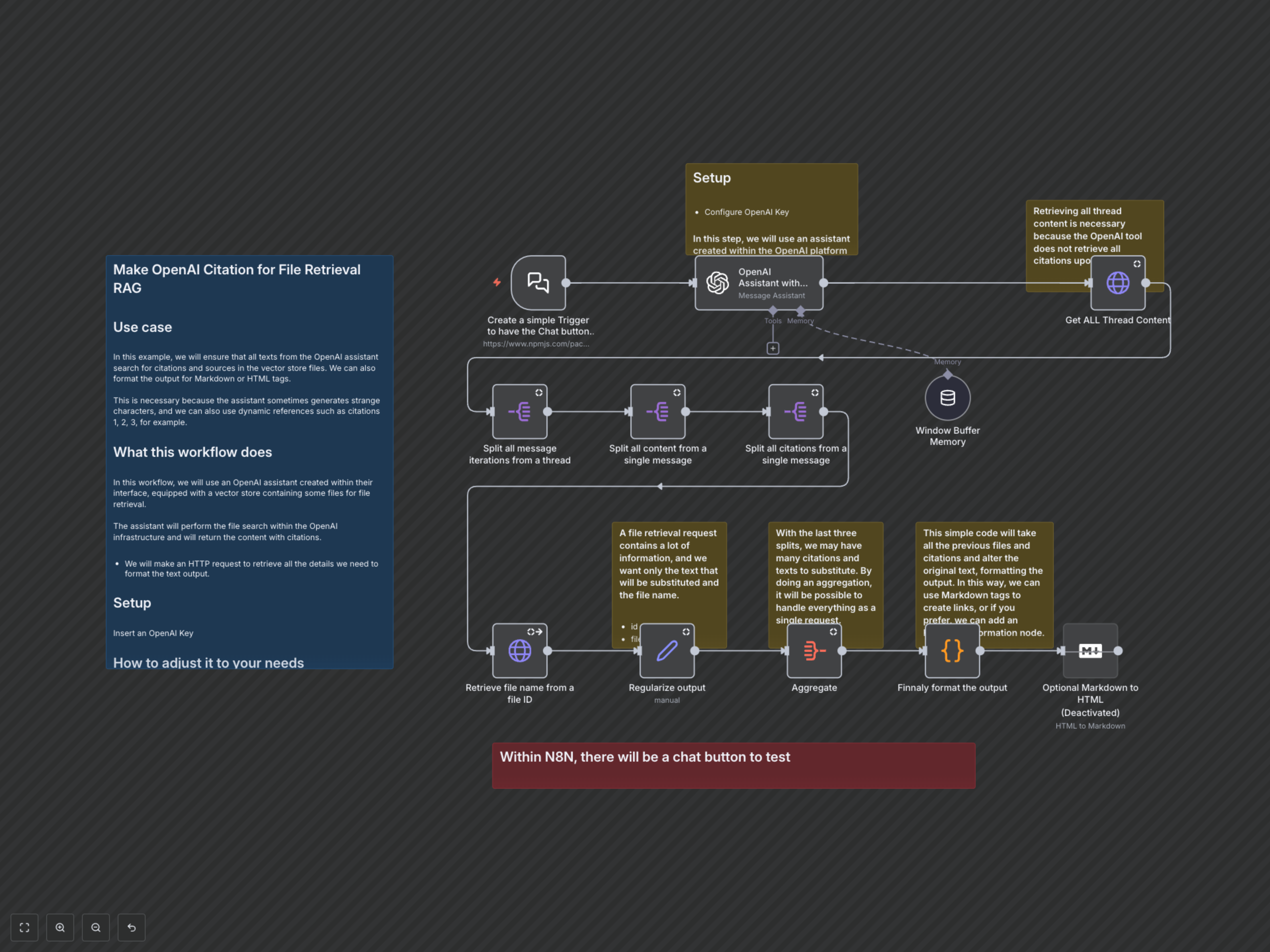
- Dynamische Zitationsabrufe: Extrahiert automatisch alle Zitierdetails und Quell-Datei-IDs aus den OpenAI-Assistenten-Threads und überwindet so anfängliche API-Ausgabe-Beschränkungen.
- Intelligente Quellenangabe: Ruft Originaldateinamen für zitierte Inhalte ab und bietet klare, für Menschen lesbare Referenzen im generierten Text.
- Anpassbare Ausgabeformatierung: Ersetzt rohe Zitier-Tags durch dynamische Referenzen wie _(Dateiname)_ und bietet eine optionale Markdown-zu-HTML-Konvertierung für vielseitigen Einsatz.
- Verbesserte RAG-Genauigkeit: Stellt sicher, dass jede Information auf ihre Quelle im Vektorspeicher zurückgeführt werden kann, wodurch Vertrauen und Zuverlässigkeit der KI-generierten Inhalte erhöht werden.
Funktionsweise
Dieser Arbeitsablauf wird über einen einfachen Chat-Trigger innerhalb von n8n gestartet, der Benutzereingaben an einen OpenAI-Assistenten weiterleitet, der mit einem Vektorspeicher für den Dateiabruff konfiguriert ist. Nachdem der Assistent eine Antwort erzeugt hat, sendet der Workflow proaktiv eine HTTP-Anfrage an die OpenAI-API, um alle Thread-Nachrichten und deren zugehörige Zitate abzurufen, da die ursprüngliche Assistenten-Ausgabe unvollständig sein kann. Anschließend werden diese Daten sorgfältig aufgeteilt, um einzelne Nachrichten, Inhalte und Zitationsanmerkungen zu isolieren. Für jede Zitation wird über einen weiteren OpenAI-API-Aufruf der entsprechende Dateiname aus Ihrem Vektorspeicher abgerufen. Alle abgerufenen Zitierdetails (Originaltext, Datei-ID, Dateiname) werden dann zusammengeführt. Abschließend ersetzt ein Code-Node intelligent die rohen Zitationsplatzhalter in der Assistentenausgabe durch formatierte, dateinamenbasierte Referenzen, wodurch eine hochpräzise und professionelle Antwort entsteht. Ein optionaler Node kann diese Markdown-Ausgabe dann in HTML konvertieren, um eine breitere Nutzung zu ermöglichen.