Automatisieren Sie Ollama-Chat-Antworten für strukturierte KI-Gespräche
Die Integration lokaler großer Sprachmodelle wie Ollama für Echtzeit-Chat kann komplex sein und inkonsistente Ausgabeformate erzeugen. Dieser Workflow verbindet nahtlos n8n mit Ollama, um eingehende Chat-Nachrichten zu verarbeiten und wunderschön strukturierte JSON-Antworten zurückzugeben, die für jede nachgelagerte Anwendung bereit sind.
Documentation
Übersicht über den Ollama-Chat-Workflow
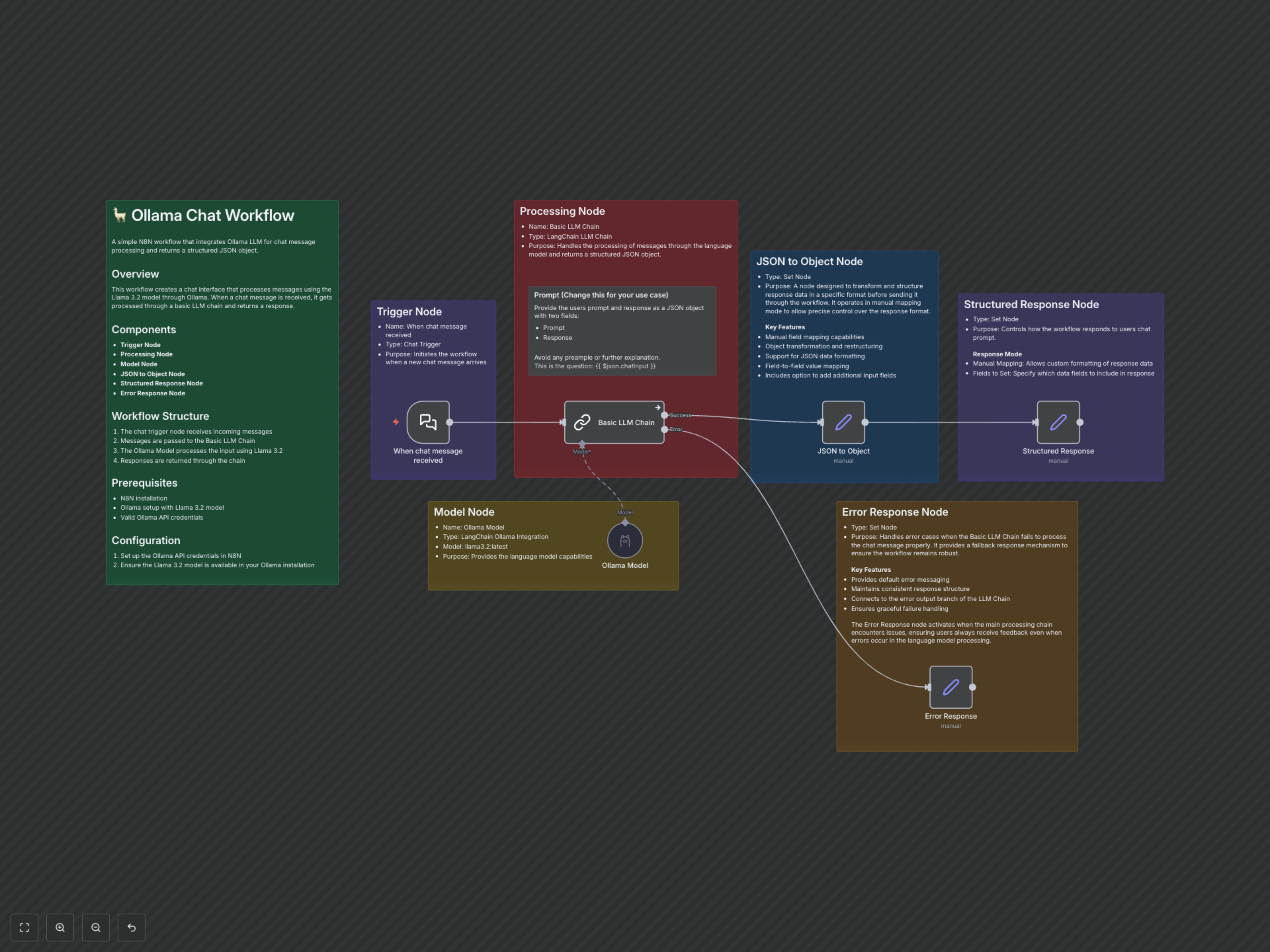
Dieser n8n-Workflow bietet eine robuste Lösung für die Integration der lokalen großen Sprachmodelle von Ollama in Ihre automatisierten Chat-Prozesse. Er erfasst eingehende Nachrichten, verarbeitet sie mit einem Llama 3.2 Modell und liefert eine saubere, strukturierte JSON-Ausgabe, die die KI-Interaktion effizient und zuverlässig macht.
Hauptmerkmale
- Automatisiertes Auslösen von Chatnachrichten für sofortige Antworten.
- Nahtlose Integration mit Ollama und dem Llama 3.2 Modell.
- Generierung strukturierter JSON-Antworten, einschließlich Felder für Eingabeaufforderung und KI-Antwort.
- Robustes Fehlerhandling zur Sicherstellung eines kontinuierlichen Betriebs.
- Anpassbare LLM-Ketten-Eingabeaufforderung für vielfältige Anwendungsfälle.
Funktionsweise
Der Workflow beginnt mit dem Knoten 'When chat message received', der Benutzereingaben sofort erfasst. Diese Eingabe fließt in die 'Basic LLM Chain', die die Interaktion mit dem Ollama-Sprachmodell orchestriert. Der Knoten 'Ollama Model', konfiguriert mit llama3.2:latest, verarbeitet die Nachricht basierend auf einer definierten Eingabeaufforderung und weist es an, die Eingabeaufforderung des Benutzers sowie seine eigene Antwort im JSON-Format zurückzugeben. Nach der Verarbeitung analysiert der Knoten 'JSON to Object' die Rohtextausgabe des LLM in ein nutzbares JSON-Objekt. Schließlich formatiert der Knoten 'Structured Response' dieses Objekt in eine für Menschen lesbare Chat-Antwort, während ein 'Error Response'-Knoten eventuelle Fehler in der LLM-Kette behandelt und so kontinuierliches Feedback sicherstellt.